Integrazione del framework DeepEval nel testing delle applicazioni di modelli di linguaggio per migliorare la qualità dei risultati generati
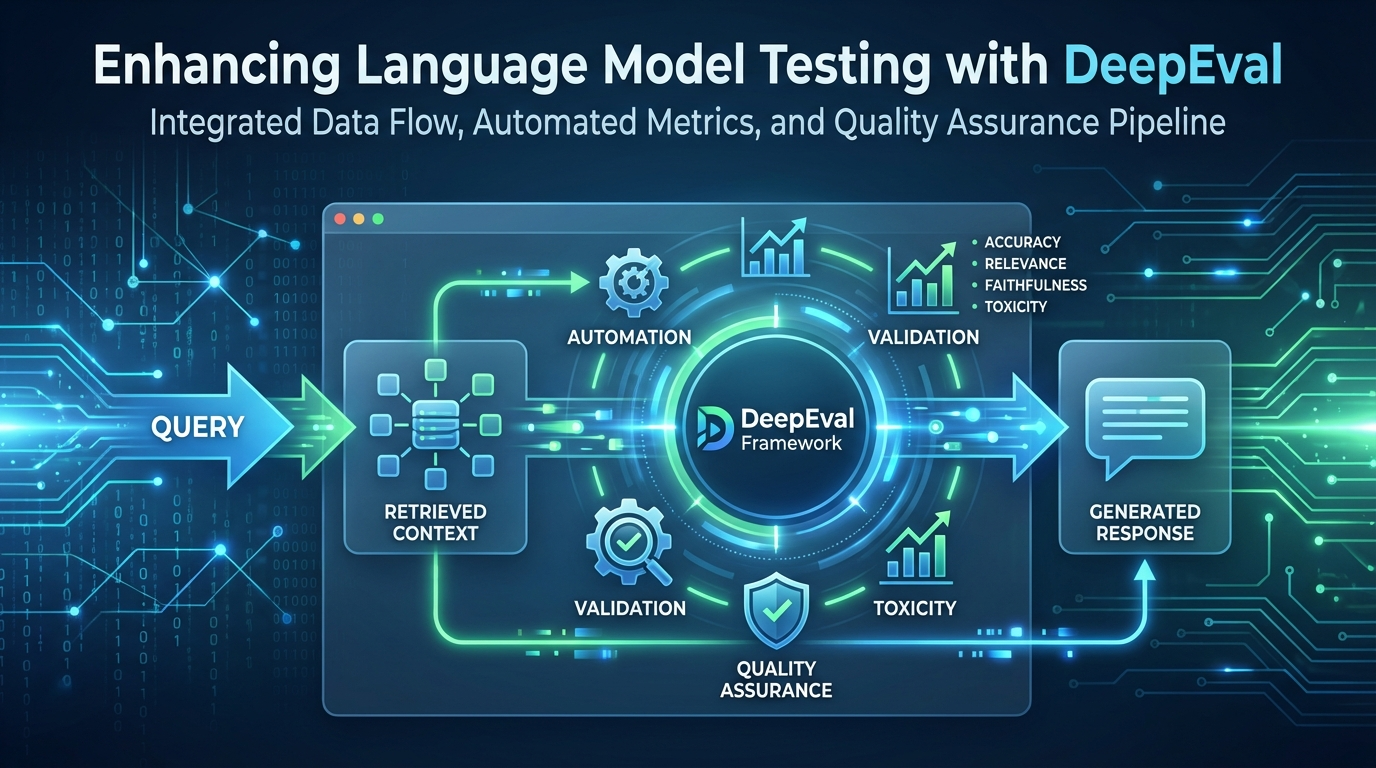
Recent sviluppi nel campo della valutazione delle applicazioni di modelli di linguaggio (LLM) hanno portato all’integrazione del framework DeepEval, progettato per migliorare la qualità dei test unitari. Questo approccio mira a rendere i risultati dei modelli testabili come codice, utilizzando metriche che valutano le prestazioni dei modelli stessi.
Il processo inizia con la configurazione di un ambiente dedicato all’implementazione del framework DeepEval. L’obiettivo è costruire una pipeline strutturata in cui ogni query, contesto recuperato e risposta generata viene validato secondo parametri rigorosi. Questo sistema si propone di superare l’ispezione manuale, automatizzando la verifica dei risultati attraverso metriche di alta qualità.
Il framework DeepEval è open-source e permette di utilizzare metriche specifiche sui modelli come “LLM-as-a-judge”, insieme a metriche personalizzate e metriche di Retrieval-Augmented Generation (RAG), come la precisione contestuale e la fedeltà. Queste metriche aiutano a determinare la qualità delle risposte generate dai modelli, in particolare se sono supportate da contesti recuperati.
Per implementare il sistema, è stata sviluppata una classe di recupero basata su TF-IDF. Questa classe trasforma i documenti in uno spazio vettoriale ricercabile, permettendo di effettuare ricerche basate sulla similarità coseno. In questo modo, è possibile ottenere i passaggi più rilevanti in risposta a una query.
In aggiunta, è stata creata una meccanica ibrida di risposta che utilizza sia un modello di linguaggio (OpenAI) per generare le risposte che un metodo estrattivo come fallback. Questo garantisce che, anche in assenza di accesso a OpenAI, il sistema possa comunque fornire risposte utili.
Il flusso di lavoro prevede la generazione di casi di test, abbinando i contesti recuperati con le risposte generate e le aspettative di verità. Successivamente, vengono configurate diverse metriche di valutazione, tra cui G-Eval e indicatori specifici per RAG, per valutare le prestazioni del sistema.
Infine, il framework esegue una valutazione complessiva, aggregando i punteggi e le relative motivazioni in un DataFrame centrale. Questo consente di identificare le aree in cui il sistema di RAG eccelle o ha bisogno di miglioramenti, offrendo una base solida per ottimizzare ulteriormente il recupero delle informazioni e la generazione delle risposte.
Il risultato finale è un sistema RAG pronto per la produzione, supportato da una rete di sicurezza basata su metriche verificabili, che permette di affrontare in modo efficace le problematiche di recupero e le allucinazioni nei risultati generati dai modelli di linguaggio.